Digital Humanities

Digital Humanities
Members of the Digital Humanities theme within AIHS combine interdisciplinary expertise spanning the digitisation of texts and collaborative digital libraries, the history of technology, computational modelling and the development of computational approaches for humanities data and cultural phenomena. Example projects include: making East Asian printed books accessible to a wider audience, modelling musical structure, exploring trust and empathy in conversational agents, researching the history of the audio CD format in the UK.
We are also part of the Digital Humanities Durham (DH steering group at Durham) and N8CIR network.
People
Dr Brian Bemman
Assistant ProfessorDr Shauna Concannon
Assistant ProfessorProfessor Alexandra I. Cristea
Professor of Computer ScienceDr Stuart James
Assistant ProfessorDr Robert Lieck
Assistant ProfessorDr Donald Sturgeon
Assistant ProfessorResearch Highlights

An AI Toolkit for Hierarchical Structure in Humanities Data
Robert Lieck
Hierarchical structure in humanities data—such as words forming phrases or musical notes shaping melodies—are central to how humans create and understand meaning. Yet, current artificial intelligence (AI) models often struggle to make such structures visible or interpretable.
The project, funded by Schmidt Sciences’ Humanities and AI Virtual Institute, develops a toolkit that helps researchers uncover and explore the latent hierarchical organisation within humanistic data, focusing on language and music. By combining advances in AI with methods tailored for interpretability, the toolkit will allow scholars in the humanities to work directly with structured models, visualise patterns in their data, and gain deeper insights into how meaning emerges from complex sequences. The project aims to bridge the gap between computational modelling and humanistic inquiry, fostering collaboration between AI researchers and scholars of language, music, and culture.
Lead PIs: Tom Lippincott (Johns Hopkins University), Meredith Martin (Princeton University), John Hale (Johns Hopkins University), Robert Lieck (Durham University)

Toward a new CCP for Arts, Humanities, and Culture research (CCP-AHC)
Eamonn Bell
CCP-AHC is a scoping and research software community-building exercise, funded by UKRI and STFC for 24 months from January 2025, with project leadership at Durham and with co-investigators at University of Brighton and STFC. Its goal is to support the sustainable and efficient development of software, pipelines, and workflows used by arts, humanities, and culture researchers who make use of UK-based digital research infrastructure (DRI). It will do so by disseminating and implementing the Collaborative Computational Project (CCP) model that has been successfully been used by many other scientific software communities over the past several decades. There is a special emphasis on ensuring that research software developed by this community makes the best of use of DRI supported by public funding, including existing and future high-performance computing (HPC) and advanced computing infrastructures supported by UKRI, UK-based HEIs and other research organisations eligible for UKRI funding.
Image: Cristóbal Ascencio & Archival Images of AI + AIxDESIGN https://betterimagesofai.org https://creativecommons.org/licenses/by/4.0/
Premodern China in the digital age
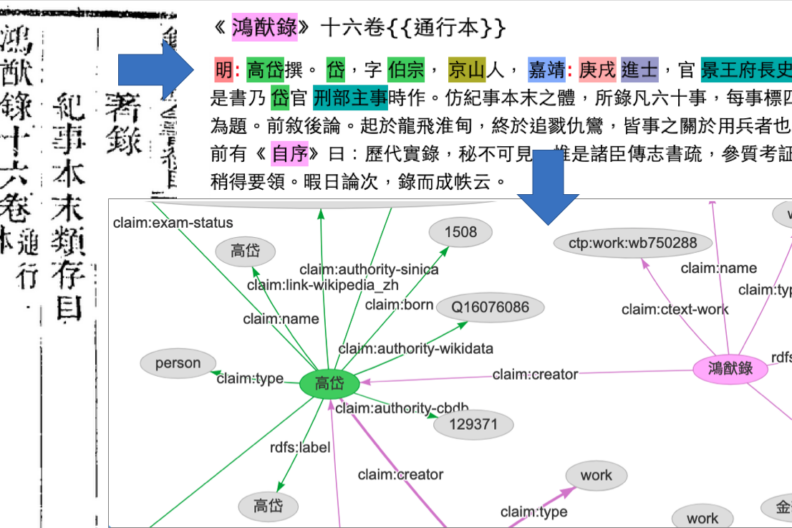
Donald Sturgeon
Building on experience and data produced while creating the Chinese Text Project digital library (Wikipedia), my current work continues to focus on applying digital technologies to aid in our understanding of the language and history of premodern China. Recently this has included applying crowdsourcing to the task of creating Linked Open Data to record structured, precise, and explicitly sourced data on historical people, events, bureaucratic structures, literature, geography and astronomical observations evidenced in early Chinese texts. Ongoing work involves creating Natural Language Processing models sufficiently accurate to greatly augment the accessibility of premodern texts to modern readers, and evaluating the effects of different types of computer-mediated reading assistance offered to readers of historical literature.

Opening the Red Book
Eamonn Bell
Drawing on science and technology studies (STS), computer science, and digital media studies, this ongoing research project charts the international research and development effort that culminated in the specification of the audio CD format in 1980, often known as the “Red Book.”
Since its introduction, musicians, artists, and other researchers have successfully damaged CDs and tampered with their players, creating new forms of music and digital media practice in their wake. By exposing the limitations and error conditions of a quotidian digital technology, these practices often serve the critique of new digital artifacts.
Whether digging into the technical details of the CD audio standard, exploring mid-90s Web archives, or conducting oral history interviews, it takes an interdisciplinary approach to fully understand these intriguing objects and the practices they afford. This project has been funded by the Irish Research Council (2019–2021) and Durham University (2022–2023).
A Recipe for Perceived Emotions in Music
Annaliese Micallef Grimaud
Have you ever listened to an unfamiliar piece of music and perceived it as sounding sad or happy? The answer is probably yes.
A common follow-up question is: How does this work?
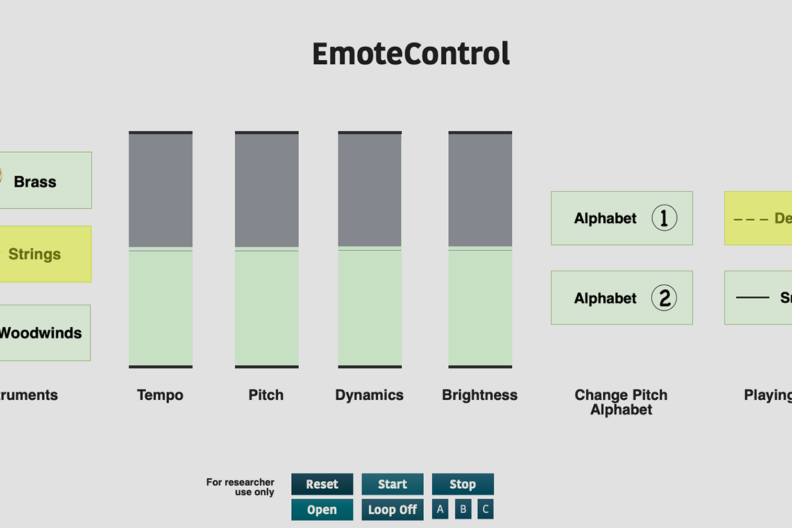
One of my research projects involved looking at how different musical features such as tempo and loudness are used to embed different emotions in a musical piece. This was attained by letting music listeners themselves show me how they think different emotions should sound like in music, by asking them to change instrumental tonal music in real-time via a combination of six or seven musical features using a computer interface I created called EmoteControl. This work identified how different combinations of tempo, pitch, dynamics, brightness, articulation, mode, and later, instrumentation, helped convey different emotional expressions through the music.
Find out how 6 musical features were used to convey 7 emotions (anger, sadness, fear, joy, surprise, calmness, and power) and whether they were successful or not here: https://journals.sagepub.com/doi/10.1177/20592043211061745
Find out how the same 6 musical features plus the option to change the instrument playing were used to convey the same 7 emotions here: https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0279605